Visualization of DriveMoE (built upon Drive-π0) on the Bench2Drive benchmark. Vision MoE selects camera views contextually, defaulting to rear view if no critical view is identified. Action MoE activates the top-3 experts based on routing scores.
Abstract
End-to-end autonomous driving (E2E-AD) demands effective processing of multi-view sensor data and robust handling of diverse and complex driving scenarios, particularly rare maneuvers such as aggressive turns. The recent success of the Mixture-of-Experts (MoE) architectures in Large Language Models (LLMs) demonstrates that expert specialization enables strong scalability. In this work, we propose \textbf{DriveMoE}, a novel MoE-based E2E-AD framework, with a Scene-Specialized Vision MoE and a Skill-Specialized Action MoE. First, we introduce Drive-π0, a Vision-Language-Action (VLA) baseline adapted from Embodied AI for autonomous driving, which serves as the foundation model for DriveMoE. Building on this, we strengthen perception through a carefully designed Vision MoE, where a router adaptively selects context-relevant camera views. This mechanism is inspired by human driving cognition, in which attention is directed to key visual cues rather than to all sensory inputs simultaneously. Beyond perception, we introduce an Action MoE that augments the framework by training a router to activate specialized expert modules tailored to distinct driving behaviors. Within the Action MoE, we implement two distinct styles(Token-level Router and Trajectory-level Router) and extensively explore their applicability in autonomous driving. In Bench2Drive closed-loop evaluations, DriveMoE demonstrates robust performance across diverse driving scenarios, alleviates the mode-averaging effect that limits existing models, and achieves state-of-the-art results with significant improvements over Drive-π0.
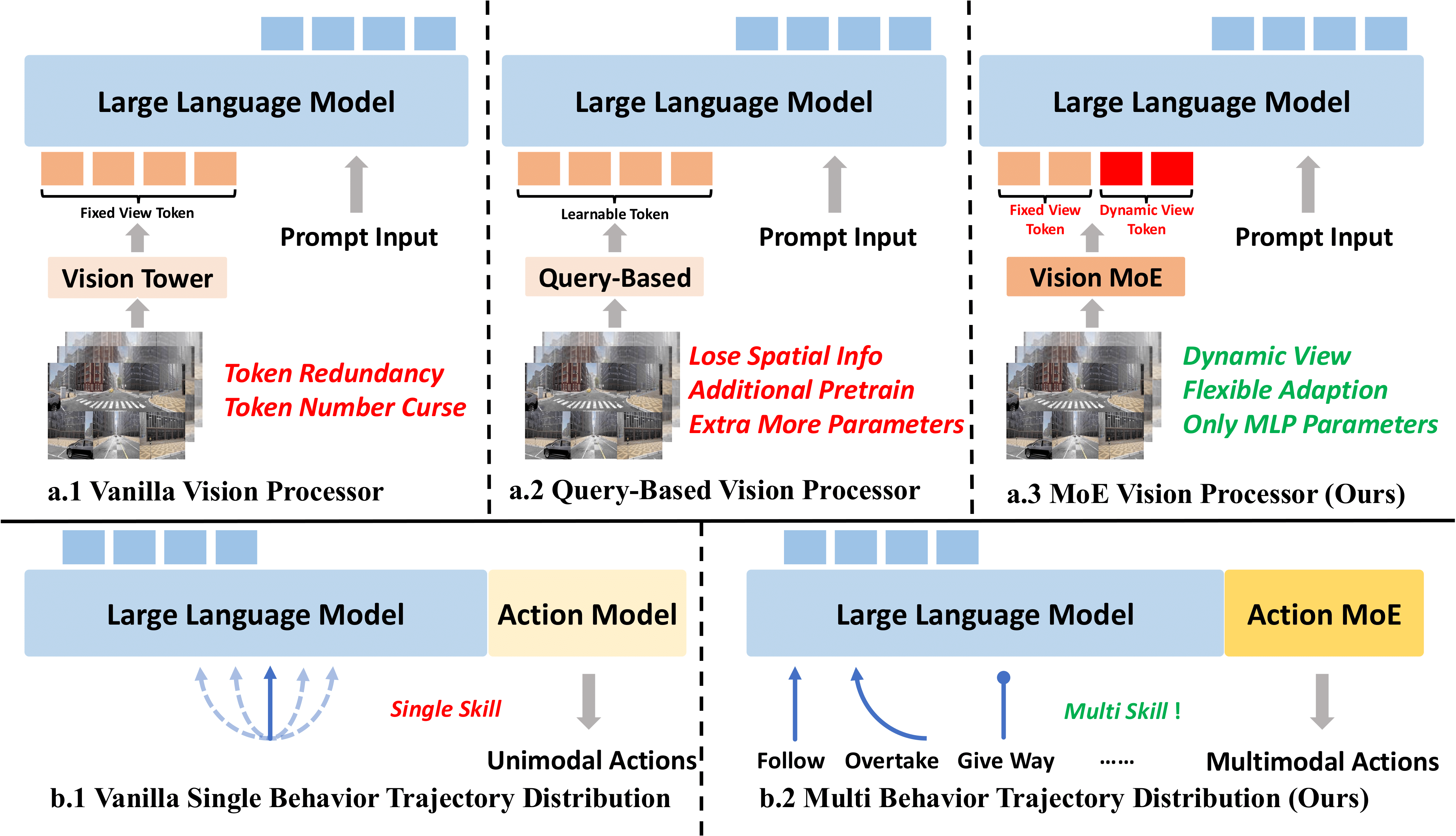
Comparison of Different Vision and Action Modeling Strategies in VLA-based End-to-End Driving.
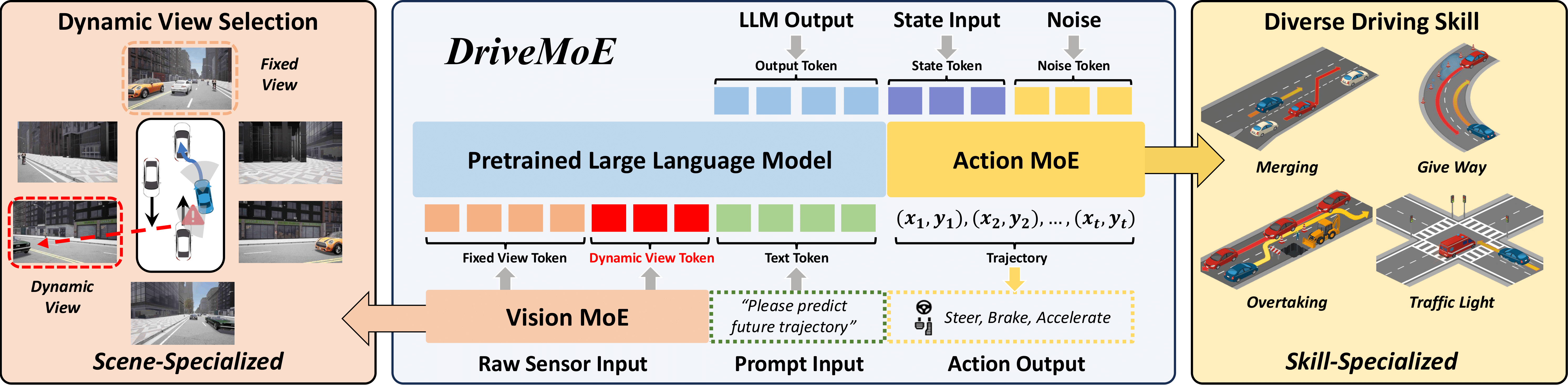
Framework of DriveMoE.
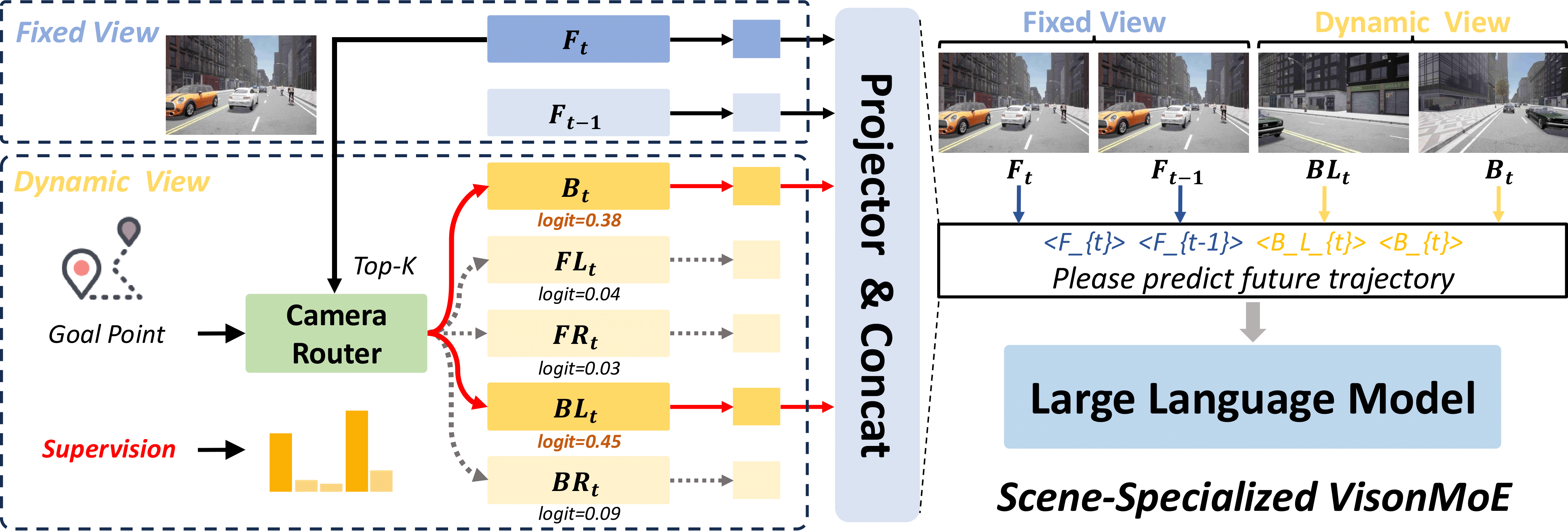
The Scene-Specialized Vision Mixture-of-Experts.
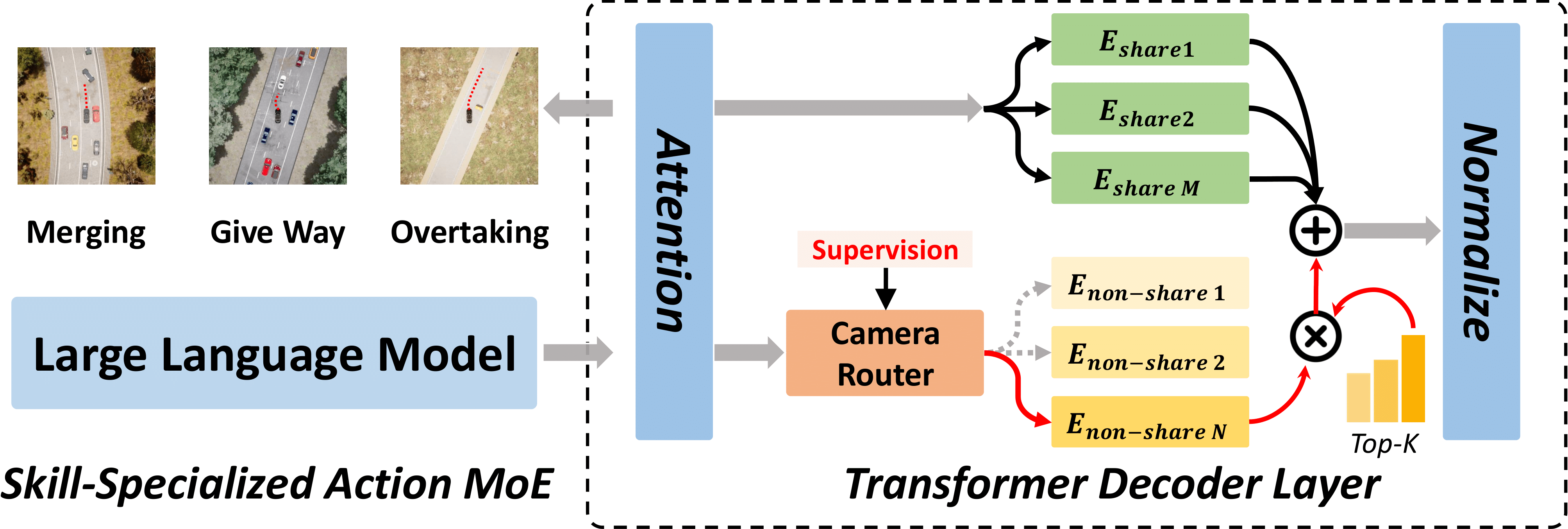
Skill-Specialized Action Mixture-of-Experts.
Challenging Corner Case Results
ParkingExit
ConstructionObstacleTwoWays
InterurbanActorFlow
SignalizedJunctionLeftTurnEnterFlow
BibTeX
@InProceedings{Yang_2026_CVPR,
author = {Yang, Zhenjie and Chai, Yilin and Jia, Xiaosong and Li, Qifeng and Shao, Yuqian and Zhu, Xuekai and Su, Haisheng and Yan, Junchi},
title = {DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2026},
pages = {10678-10688}
}