Baselines
Data Analysis
We used Bench2Drive-VL to evaluate popular VLMs. The scales selected are around 3B, since we think larger VLMs are difficult to run in autonomous driving systems.
Results under dev10 routes (an 80s early stop is used, so the success rate is lower than normal evaluation methods):
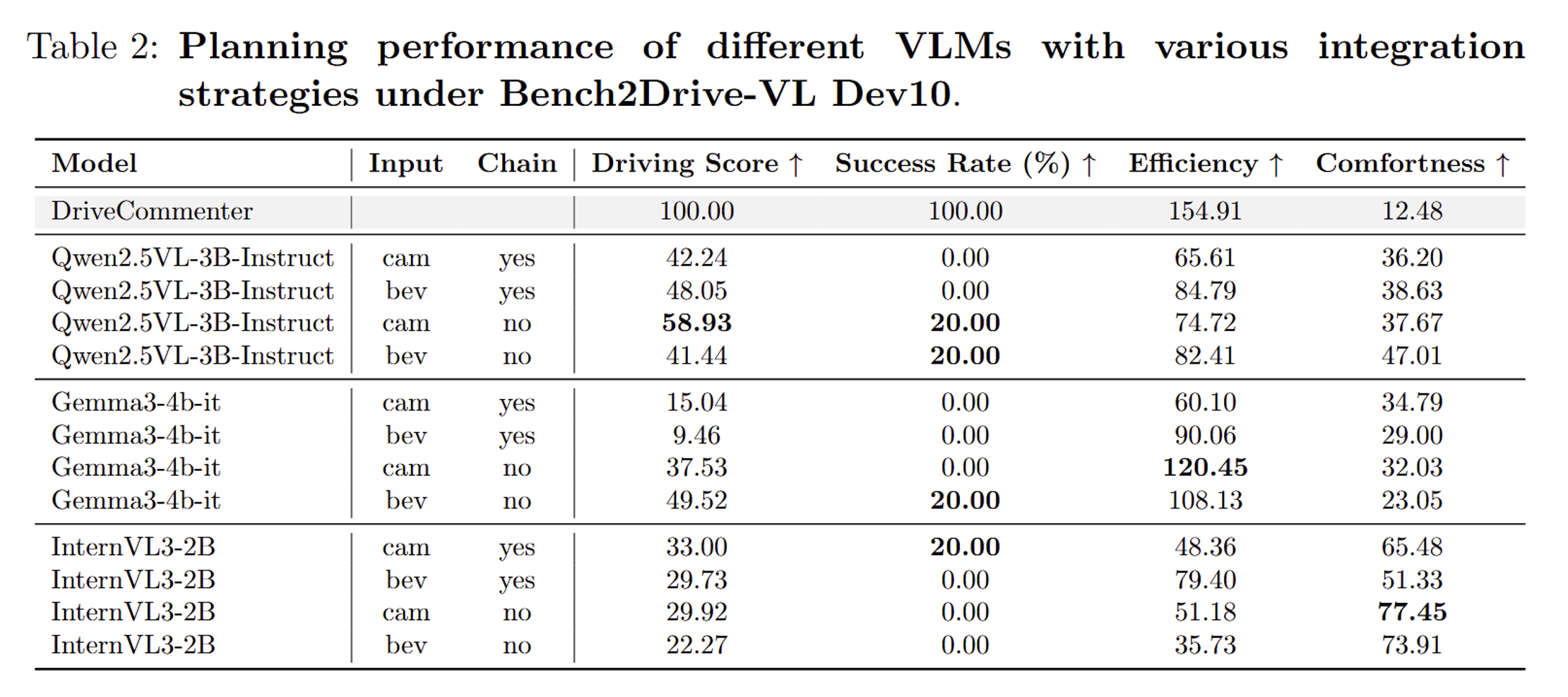
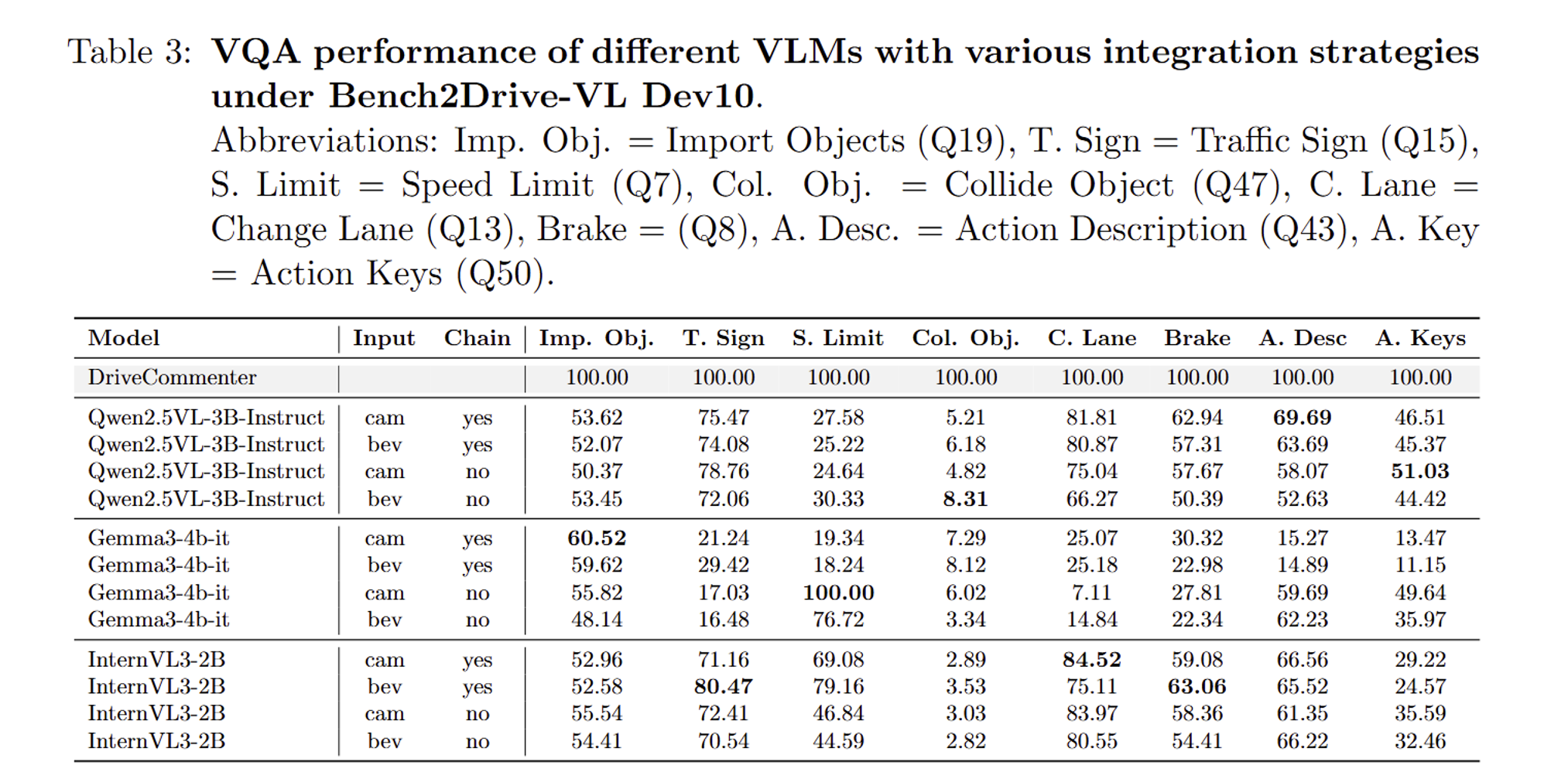
Using our adapting strategy, these VLMs still lag behind the current SOTA. However, they have already reached the performance level of traditional end-to-end approaches. Sadly, Chain-of-thought reasoning does not show a clear advantage on these models, and longer context lengths tend to increase hallucinations. For example, the speed limit score of Gemma3-4b-it with/without chain shows this obviously.
Limitations
In Bench2Drive-VL, the control strategy of VLMs for vehicles is relatively simple, and the implementation of chain-of-thought reasoning is rather rudimentary, which may affect the performance of the VLMs. Moreover, the experiments were conducted only on smaller-scale models, the capabilities of larger models require further research.