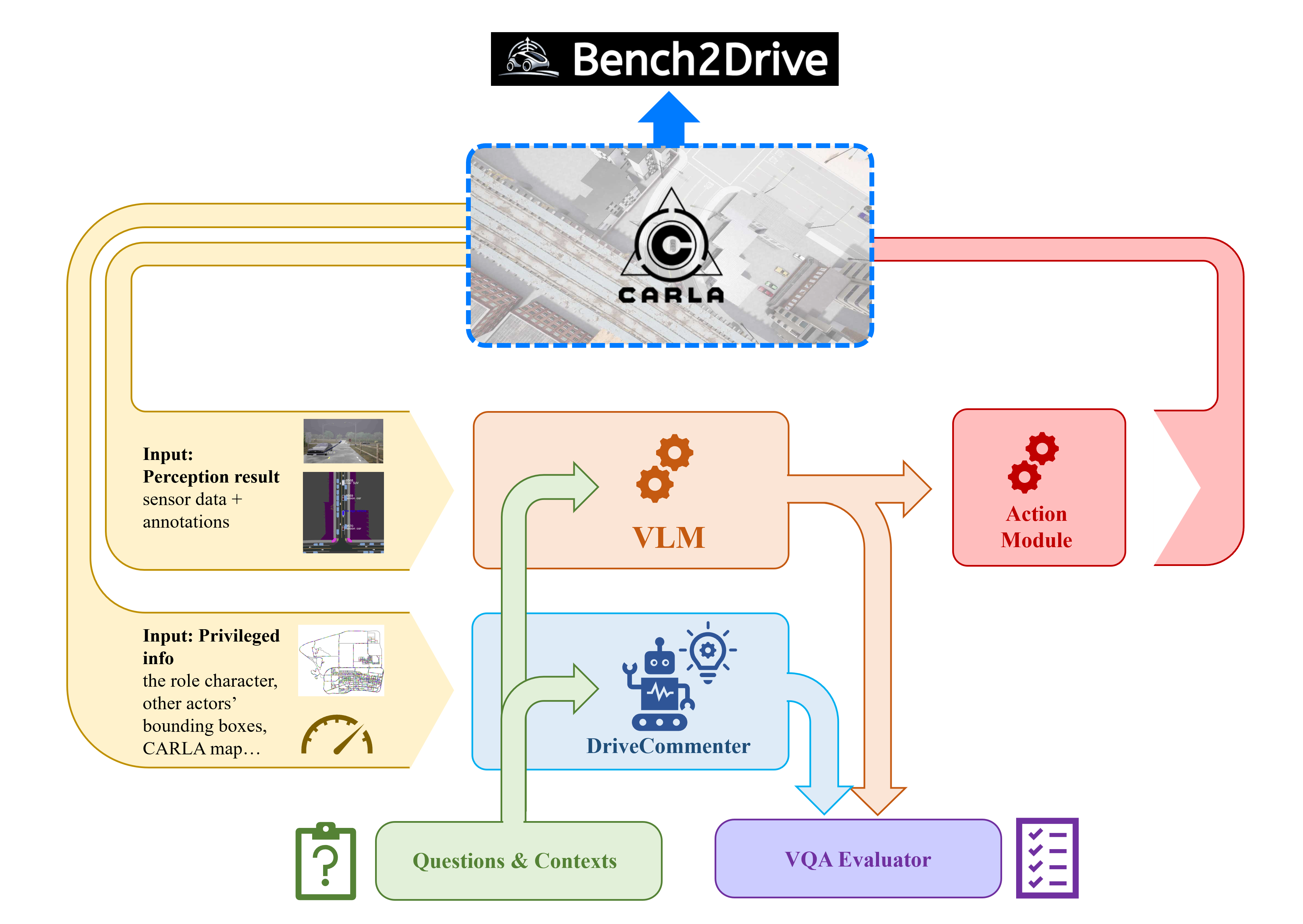
Closed-Loop Inference
When doing closed-loop inference, Bench2Drive-VL will apply DriveCommenter to generate real time VQAs, then let the VLM to control the ego vehicle. Question details, ground truths and VLM's answers of VQAs will be saved under ./output for latter evaluation. For planning section, we utilize the original Bench2Drive metrics.
Write a VLM config file
Write a vlm config file:
{
"TASK_CONFIGS": {
"FRAME_PER_SEC": 10 // sensor saving frequency
},
"INFERENCE_BASICS": {
"INPUT_WINDOW": 1, // frame count of given image input
"CONVERSATION_WINDOW": 1, // not used anymore, to be removed
"USE_ALL_CAMERAS": false, // true if use all cameras as input
"USE_BEV": false, // true if use bev as input
"NO_HISTORY_MODE": false // do not inherit context of previous VQAs
},
"CHAIN": { // for inference
"NODE": [19, 15, 7, 24, 13, 47, 8, 43, 50],
"EDGE": { // "pred": succ
"19": [24, 13, 8],
"15": [7, 8],
"7": [8],
"24": [13, 47],
"13": [47, 8, 43],
"47": [8],
"8": [43],
"43": [50],
"50": []
},
"INHERIT": { // inherit context from last frame
"19": [43, 7],
"15": [7]
},
"USE_GT": [24] // questions which use ground truth as answer
},
"CONTROL_RATE": 2.0, // intervene frequency of vlm
"MODEL_NAME": "api", // model name, please check out supported models
"MODEL_PATH": "../model_zoo/your_model", // model path
"GPU_ID": 0, // the gpu model runs on
"PORT": 7023, // web port
"IN_CARLA": true,
"USE_BASE64": true, // if false, local path is used for transmitting images
"NO_PERC_INFO": false // do not pass extra perception info to vlm via prompt
}
Please refer to supported vqas for question ids.
Please refer to supported models.
Make sure you include question 50 because the action module requires its answer.
Write a start up script
Write a start up script for inferencing framework:
If you want a quickstart, you can set MINIMAL=1 to run Bench2Drive-VL without VLM. In this mode, DriveCommenter will take control of the ego vehicle.
#!/bin/bash
BASE_PORT=20082 # CARLA port
BASE_TM_PORT=50000 # CARLA traffic manager port
BASE_ROUTES=./leaderboard/data/bench2drive220 # path to your route xml
TEAM_AGENT=leaderboard/team_code/data_agent.py # path to your agent, in B2DVL, the agent is fixed, so don't modify this
BASE_CHECKPOINT_ENDPOINT=./my_checkpoint # path to the checkpoint file with saves sceanario running process and results.
# If not exist, it will be automatically created.
SAVE_PATH=./eval_v1/ # the directory where seonsor data is saved.
GPU_RANK=0 # the gpu carla runs on
VLM_CONFIG=/path/to/your_vlm_config.json
PORT=$BASE_PORT
TM_PORT=$BASE_TM_PORT
ROUTES="${BASE_ROUTES}.xml"
CHECKPOINT_ENDPOINT="${BASE_CHECKPOINT_ENDPOINT}.json"
export MINIMAL=0 # if MINIMAL > 0, DriveCommenter takes control of the ego vehicle,
# and vlm server is not needed
export EARLY_STOP=80 # When getting baseline data, we used a 80s early-stop to avoid wasting time on failed scenarios. You can delete this line to disable early-stop.
bash leaderboard/scripts/run_evaluation.sh $PORT $TM_PORT 1 $ROUTES $TEAM_AGENT "." $CHECKPOINT_ENDPOINT $SAVE_PATH "null" $GPU_RANK $VLM_CONFIG
When running closed-loop inference, sensor data will be saved under ${SAVE_PATH}/model_name+input/, VQA generated by DriveCommenter will be saved under outputs/vqagen/model_name+input/, VLM's inference results will be saved under outputs/infer_results/model_name+input/.
Start VLM Server
You don't need to do this step if you set MINIMAL=1.
Start the web server for your vlm:
python ./B2DVL_Adapter/web_interact_app.py --config /path/to/your/vlm_config.json
Start to inference
Run the start up script you just wrote:
bash ./startup.sh